Project Dir Visibility Duet3_V06
-
I have a problem with understanding a project setting, branch RepRapFirmware-3.02-dev:
if I set Build Configurations - set Active - Duet3_V06, the folder src\Duet_V06 is grayed out with the default settings for Resource Configurations - Exclude from Build. But When I disable set RADDS_RTOS from excluding, the folder is visible, even when I exclude the Duet3_V06 in the exclude list. I don't understand it, can someone help me to understand please?wrong setting, but Duet_V06 folder visible:
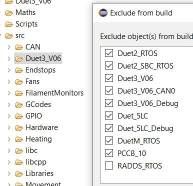
default setting and Duet3_V06 active, folder should be visible:
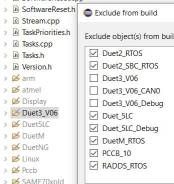
This wrong activation has worse effects than only this subfolder, e.g. the flag SUPPORT_ASYNC_MOVES is not set for all the other files and grayed out.
-
Which version of Eclipse C++ are you using? I recently upgraded to 2020-06.
I find that some versions of Eclipse occasionally grey out the wrong folder after changing configurations. Changing to a different configuration and back again normally fixes it.
Duet WiFi hardware designer and firmware engineer
Please do not ask me for Duet support via PM or email, use the forum
http://www.escher3d.com, https://miscsolutions.wordpress.com -
@dc42 thanks for your proposal, I used 201912, and will try now 2020-06 also. Strangely it compiles ok with the wrong graying, and wrong when I change the folder so it is displayed correctly.
I tested 202006 now, unfortunately the same problem, but compilation is correct and in the compiled Duet3_V06\src are the Pins_Duet3_V06.d/.o/.su files. I tried importing new, closing and cleaning without change.
-
When I throw out every Target in Build Configuration - Manager with exception of the three Duet3_V06 targets, the folder Duet3_V06 is visible correctly, the build compiles correctly, SUPPORT_ASYNC_MOVES is handled correctly now.
(But it compiles some additional unneccesary targest of the depending projects. I can live with that)*)*) edit: the unneccesary targets which are built in addition are the targets which are the defaults of the projects, so removing unnessary targets in those projects will probably solve this also.
-
@JoergS5 said in Project Dir Visibility Duet3_V06:
But it compiles some additional unneccesary targest of the depending projects. I can live with that
Yes, I that happen a lot too.