Crashes during printing - "SPI connection has been reset".
-
Just half an hour ago it happened again, 3 hours into a perfectly fine print.
Happens on absolutely random positions and not very often.
Think this was the third time, so lets say it happens on 1 out of 10 prints, sometimes minutes after starting, sometimes hours into the print. I checked what gcode lines were executing and there's nothing special. It stopped half way through a simple G1 Move/Extrude.As DWC / network connection would always crash in this case, I used the touch panel to run M115 and M122 and took photos:
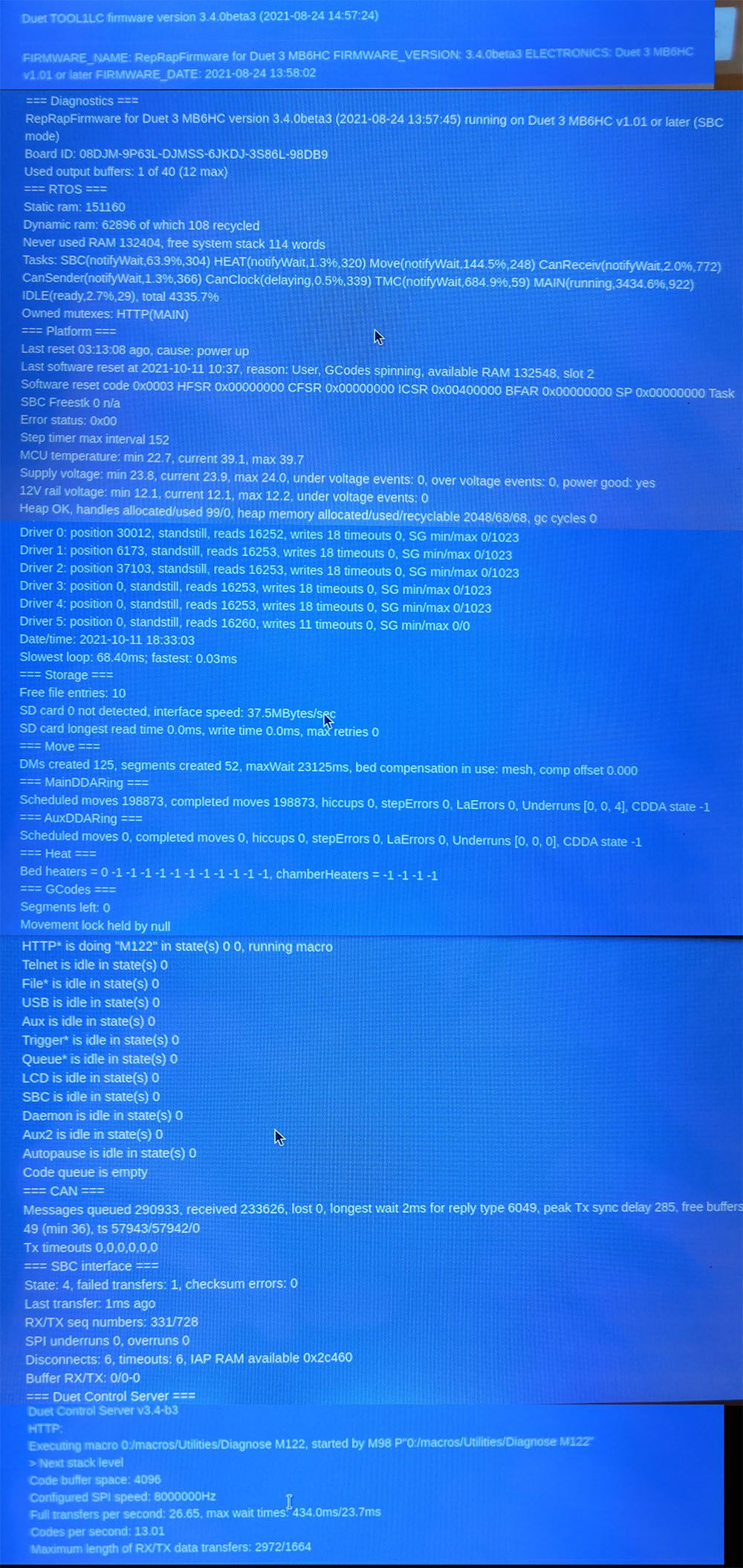
Then I set up USB/Serial connection to the 6HC using YAT.
M115:
FIRMWARE_NAME: RepRapFirmware for Duet 3 MB6HC FIRMWARE_VERSION: 3.4.0beta3 ELECTRONICS: Duet 3 MB6HC v1.01 or later FIRMWARE_DATE: 2021-08-24 13:58:02After that, the console continued to log...
(19:36:07.449) Lost connection to Linux
(19:36:07.948) Connection to Linux established!
(19:37:02.172) Lost connection to Linux
(19:37:02.668) Connection to Linux established!
(19:37:56.846) Lost connection to Linux
(19:37:57.383) Connection to Linux established!
(19:38:51.540) Lost connection to Linux
(19:38:52.103) Connection to Linux established!With a bit less than 60 seconds in between, these messages seem to correlate with the SPI error messages.
Then I did a M112 instead of a M122 - emergency reset. DAMN.
M112 showed an interesting behavior again:- 6HC reacted to it and seemed to restart
- the panel connected to the pi reacted too - however the panels only reaction was showing the overlay stating it is trying to reconnect.
- Toolboard red LED was blinking fast
Then nothing more happened.
Sent a M115 again, same result as before, nothing else happened.Then sent a M122 with more unexpected results.
- 6HC reacted to it again (could hear it as the attached fans reduced speed)
- pi/panel ended displaying the reconnect dialog, console logs SPI connection reset warning every ~55 seconds again.
- toolboard started to blink slowly again stating it's connected again
- M122 did not log anything though
- 6HC seems not to react to serial commands anymore.
- Interestingly, the pi->duet connection seems to PARTIALLY work. I was able to control the hotend heater using the panel.
Reconnected terminal and sent M122 again, this time it returned data.
The "Last software reset at 2021-10-11 19:27" correlates with when I sent the M115 mentioned above.(19:35:56.159) === Diagnostics ===
(19:35:56.159) RepRapFirmware for Duet 3 MB6HC version 3.4.0beta3 (2021-08-24 13:57:45) running on Duet 3 MB6HC v1.01 or later (SBC mode)
(19:35:56.159) Board ID: 08DJM-9P63L-DJMSS-6JKDJ-3S86L-98DB9
(19:35:56.159) Used output buffers: 2 of 40 (12 max)
(19:35:56.159) === RTOS ===
(19:35:56.159) Static ram: 151160
(19:35:56.159) Dynamic ram: 62680 of which 324 recycled
(19:35:56.159) Never used RAM 136460, free system stack 190 words
(19:35:56.159) Tasks: SBC(notifyWait,0.4%,326) HEAT(notifyWait,0.0%,320) Move(notifyWait,0.0%,276) CanReceiv(notifyWait,0.0%,772) CanSender(notifyWait,0.0%,374) CanClock(delaying,0.0%,339) TMC(notifyWait,7.3%,59) MAIN(running,92.2%,922) IDLE(ready,0.0%,29), total 100.0%
(19:35:56.159) Owned mutexes: USB(MAIN)
(19:35:56.159) === Platform ===
(19:35:56.159) Last reset 00:08:28 ago, cause: software
(19:35:56.159) Last software reset at 2021-10-11 19:27, reason: HardFault, GCodes spinning, available RAM 132404, slot 0
(19:35:56.159) Software reset code 0x0063 HFSR 0x40000000 CFSR 0x00000082 ICSR 0x0044a803 BFAR 0x00000038 SP 0x2041ade0 Task MAIN Freestk 1431 ok
(19:35:56.159) Stack: 00000000 2041ae78 2041ae7c 2041ae80 00000000 00472b2f 004792f0 610f0200 0a302029 6e6e7500 20676e69 7263616d ff000a6f ffffffff ffffffff ffffffff ffffffff ffffffff ffffffff 2042e5c0 00000000 00000000 00000000 00000000 00000000 204291d0 00000000
(19:35:56.159) Error status: 0x00
(19:35:56.159) Step timer max interval 131
(19:35:56.159) MCU temperature: min 36.8, current 39.0, max 39.1
(19:35:56.159) Supply voltage: min 23.8, current 23.9, max 23.9, under voltage events: 0, over voltage events: 0, power good: yes
(19:35:56.159) 12V rail voltage: min 12.1, current 12.1, max 12.2, under voltage events: 0
(19:35:56.159) Heap OK, handles allocated/used 0/0, heap memory allocated/used/recyclable 0/0/0, gc cycles 0
(19:35:56.159) Driver 0: position 0, standstill, reads 41029, writes 18 timeouts 0, SG min/max 0/133
(19:35:56.159) Driver 1: position 0, standstill, reads 41030, writes 18 timeouts 0, SG min/max 0/119
(19:35:56.159) Driver 2: position 200, standstill, reads 41030, writes 18 timeouts 0, SG min/max 0/122
(19:35:56.159) Driver 3: position 0, standstill, reads 41033, writes 15 timeouts 0, SG min/max 0/0
(19:35:56.159) Driver 4: position 0, standstill, reads 41033, writes 15 timeouts 0, SG min/max 0/0
(19:35:56.159) Driver 5: position 0, standstill, reads 41037, writes 11 timeouts 0, SG min/max 0/0
(19:35:56.159) Date/time: 2021-10-11 19:35:56
(19:35:56.159) Slowest loop: 24.80ms; fastest: 0.04ms
(19:35:56.159) === Storage ===
(19:35:56.159) Free file entries: 10
(19:35:56.159) SD card 0 not detected, interface speed: 37.5MBytes/sec
(19:35:56.159) SD card longest read time 0.0ms, write time 0.0ms, max retries 0
(19:35:56.159) === Move ===
(19:35:56.159) DMs created 125, segments created 2, maxWait 2363ms, bed compensation in use: mesh, comp offset 0.000
(19:35:56.159) === MainDDARing ===
(19:35:56.159) Scheduled moves 1, completed moves 1, hiccups 0, stepErrors 0, LaErrors 0, Underruns [0, 0, 1], CDDA state -1
(19:35:56.159) === AuxDDARing ===
(19:35:56.159) Scheduled moves 0, completed moves 0, hiccups 0, stepErrors 0, LaErrors 0, Underruns [0, 0, 0], CDDA state -1
(19:35:56.159) === Heat ===
(19:35:56.159) Bed heaters = 0 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1, chamberHeaters = -1 -1 -1 -1
(19:35:56.159) === GCodes ===
(19:35:56.159) Segments left: 0
(19:35:56.159) Movement lock held by null
(19:35:56.159) HTTP* is idle in state(s) 0
(19:35:56.159) Telnet is idle in state(s) 0
(19:35:56.159) File is idle in state(s) 0
(19:35:56.159) USB is ready with "m122" in state(s) 0
(19:35:56.159) Aux is idle in state(s) 0
(19:35:56.159) Trigger* is idle in state(s) 0
(19:35:56.159) Queue is idle in state(s) 0
(19:35:56.159) LCD is idle in state(s) 0
(19:35:56.159) SBC is idle in state(s) 0
(19:35:56.159) Daemon is idle in state(s) 0
(19:35:56.159) Aux2 is idle in state(s) 0
(19:35:56.159) Autopause is idle in state(s) 0
(19:35:56.159) Code queue is empty
(19:35:56.159) === CAN ===
(19:35:56.159) Messages queued 4606, received 11159, lost 0, longest wait 2ms for reply type 6049, peak Tx sync delay 355, free buffers 49 (min 48), ts 2544/2543/0
(19:35:56.159) Tx timeouts 0,0,0,0,0,0
(19:35:56.159) === SBC interface ===
(19:35:56.159) State: 4, failed transfers: 0, checksum errors: 0
(19:35:56.159) Last transfer: 10ms ago
(19:35:56.159) RX/TX seq numbers: 6175/1699
(19:35:56.159) SPI underruns 0, overruns 0
(19:35:56.159) Disconnects: 9, timeouts: 9, IAP RAM available 0x2c42c
(19:35:56.159) Buffer RX/TX: 0/0-0
(19:35:56.159) okSSHing onto the pi / accessing DWC by network still was impossible.
-
Tried to find out more on the Pi side, but as it disconnected from network permanently, I cannot ssh onto it without a full restart, which will likely wipe relevant temp data.
yeah. Not much left to analyze.
For better preparation for a next crash I have tweaked log settings:- /opt/dsf/conf/config.json -> logLevel = debug
- /etc/systemd/journald.conf -> Storage=persistent
-
Updated to the latest beta 4. Reading through the changelog I don't think it will change anything regarding the SPI connection issue.
Any ideas how to continue debugging next time it happens?
What technical reason is there for the SPI connection failure message to appear? -
@jbjhjm Those log settings are far from ideal and in fact I got the same symptoms with persistent logging and long prints as well. The reason is that systemd flushes lots and lots of messages to the SD card in regular intervals, which probably stalls IO access and/or the stdout line at some point (due to the massive amount of log messages; more than 3x the regular G-code file length per print). Either reset LogLevel back to "info" or change the journald storage to "volatile".
When DCS becomes unresponsive at some point (probably during a full SPI transfer and longer than 500ms), RRF thinks the Pi lost communication so it invalidates everything.
If the resets persist with the standard log level, try out a different SD card and/or reduce IO load on the Pi as far as possible.
-
@chrishamm oh dear, thanks for the warning. Will revert the log settings to be more lightweight.
I did only tweak these yesterday, so all crashes until now happened with standard log settings.
I'm using the SD card shipped with the 6HC, but can try to get a different one.So your guess is the error appears because the Pi is too busy to respond to RRF in time?
Besides the RRF communication it handles streaming camera data. I can try to lower fps/resolution. -
@jbjhjm Yes, I think so. If the logging provider hangs during SPI transfers, it's likely to reset the connection state.
-
Experienced a crash again, this time it's been different though.
Duet suddenly stated the print was 100% done. No other errors.I was not able to do a M115 / M122 this time, but the Raspi still has persistent logging enabled.
I will check these logs later and see if anything useful is in there.One thing making me suspicious is I'm having a terrible lot of network disconnects.
Whenever a print fails, DWC is offline too, and outside of erronous situations DWC/Webcam sometimes reacts very slow too.I'll do some investigation on how to monitor CPU and network load on the Pi.
-
@jbjhjm its also worth ensuring you are giving the Pi enough voltage. look for undervoltage events in the logs
-
@t3p3tony thank you, will do!
I applied a number of changes today, let's see how they work out:
- using 3.4.0b5 now
- disabled logging as suggested by @chrishamm - my yesterday's print logged a whopping 1.5 GB.

- reduced webcam resolution
- installed htop to track CPU/Mem performance
- [external] modified my wifi setup; a wifi repeater was causing network performance issues. It would not surprise me if it also affected DWC / pi performance
htop stats say that 70-90 % of CPU load is caused by a chromium process. Unfortunately chromium always runs many parallel processes so it is difficult to investigate what this is actually doing.
-
@jbjhjm if you are not running DWC local to the Pi then you can obviously not run chromium at all. If you are running DWC on that Pi then see what its at with only DWC open
-
@t3p3tony no voltage issues reported so far by vcgencmd.
I'm not sure I understand what you meant with your last comment.DWC is running on the Pi (at least as far as I understand Duet's SPC mode, all that is handled by the Pi while the mainboard only handles printing and reports back values?).
DWC also is the only opened chromium tab.
Nontheless chromium runs a bunch of different processes.
In Time/CPU columns you can see though that there is just one chromium process that uses lots of CPU time.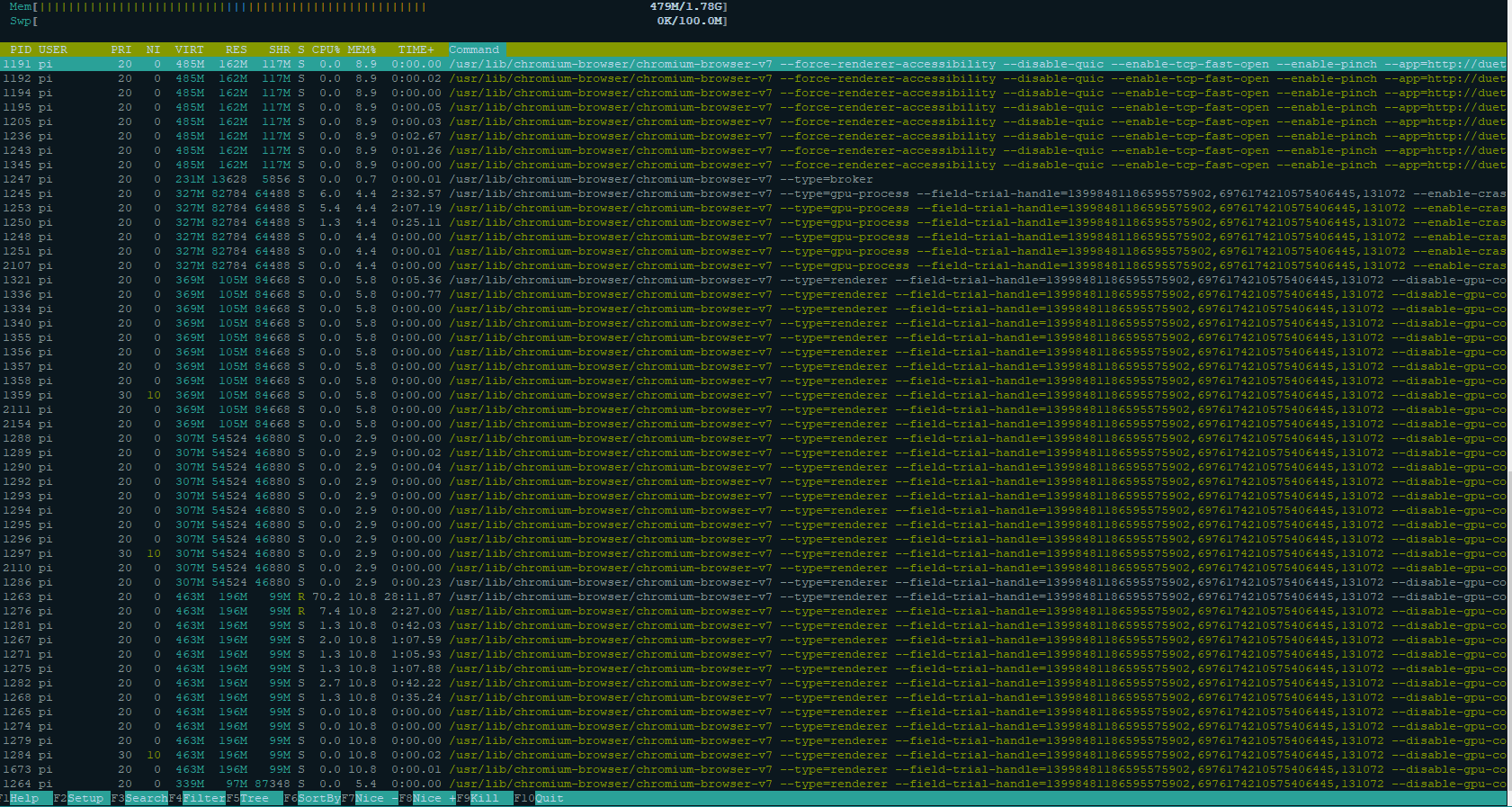
-
@jbjhjm I mean are you running the Pi headless and connecting via a network interface on the Pi to the webserver, or do you have a screen connected to a pi and running DWC in a browser on the Pi?
-
@t3p3tony ah now I get you. It's both, the pi has a permanently attached screen, and I often access DWC through network too for more complex tasks and if I'm not in the same room.
-
ok it seems that the pi's network connection has again crashed just a few minutes ago; it's still listed in the routers active devices list, responds to pings, but DWC does not load anymore. The print is still being executed though.
So I checked what happened on the touch panel: Chrome displayed a white page + a note that it has crashed and if it should reload.
Now this is weird: I dismissed that message, exited fullscreen and then saw another instance of Chrome running below the crashed instance!
I have no clue why it is there. I did not tweak the startup routine provided by duetPi.
After closing the crashed chrome window, it seems that the network connection was recreated too...
Nothing really useful in journal (re-enabled logging hoping to hunt down networking issues). Just way too many network connection losses and reconnects. This is related to the bad wifi that I still have to improve. Disallowed auto-switching frequency bands and 2.4/5Ghz, hopefully that will make the connection a bit more robust. -
@jbjhjm I hope @chrishamm has some ideas about what to look for in the logs as a cause of this.
-
@t3p3tony when my next print is completed I'll do a full restart and check chrome status right after, if two instances are running and such.
If someone can point me into the right direction for finding the duetPi startup script, I'll check if there's anything unusual going on.Attached bootlog.txt by the way.
Don't know enough about raspi + linux to spot anything useful unfortunately. -
The duplicate chromium seems to be related to beta5.
Just did a full restart and the screen showed a crashed chromium window right away.
This has never happened before so I'm quite sure it has to do with beta5.
Opened a but report to discuss this separately.
https://forum.duet3d.com/topic/25542/3-4-b5-bug-chromium-crashes-on-startup-sbc -
@jbjhjm its not really crashed as such as I outlined in the other thread, rather its showing that chrome was not shutdown properly. I will leave discussion of that to the tother thread, but the huge number of chrome tasks is unusual and I am not seeing those.
-
@t3p3tony chrome shutdown/crash is fixed by the solution proposed in other topic!
About the number of processes, that's my fault. I just noticed that htop was showing not only processes but every thread too. I do still see a dozen processes but that is not unusual for chrome.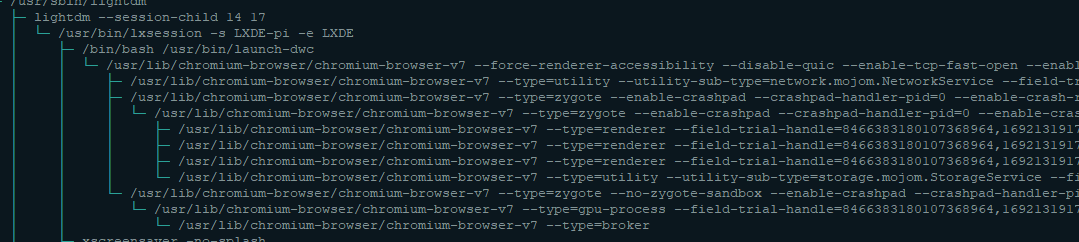
-
@jbjhjm ok, so we still need to see if you have SPI disconnect errors now.