Where is the difference - 10 times X1 vs 1 times X10
-
@arhi said in Where is the difference - 10 times X1 vs 1 times X10:
@DocTrucker it is what klipper is doing, precompiling the g-code in real-time and pushing the stepper instructions to the stepper boards... so all planning is done on the host (That can be RPI but also a 128core desktop pc with terabyte of ram
 )
)Running a real-time task such as planning on a system running a non-realtime OS and sending near real-time commands over a shared bus is IMO a dubious thing to do. But of course you can get away with it if you don't have much else competing for CPU and bus time.
Duet WiFi hardware designer and firmware engineer
Please do not ask me for Duet support via PM or email, use the forum
http://www.escher3d.com, https://miscsolutions.wordpress.com -
@droftarts that was a sad day .. I used rapman 3.0 and making rapman reliably print HDPE and PP got me into reprap core team 10 years ago
.. those were the times .. hand made hotends, revolutionary wade's extruder... ah.. memories nope's idea for heated bed ... there was a very strong community around bfb, prusa's first printer was rapman, erik that made ultimaker, first printer was rapman too .. kai parthy the guy who invented wood filled filament and all those lay* filaments was also there ... memories ... -
@dc42 said in Where is the difference - 10 times X1 vs 1 times X10:
Running a real-time task such as planning
I have not tried klipper yet so can't comment really but ppl are pretty happy with it so it kinda works. Not sure how exactly.
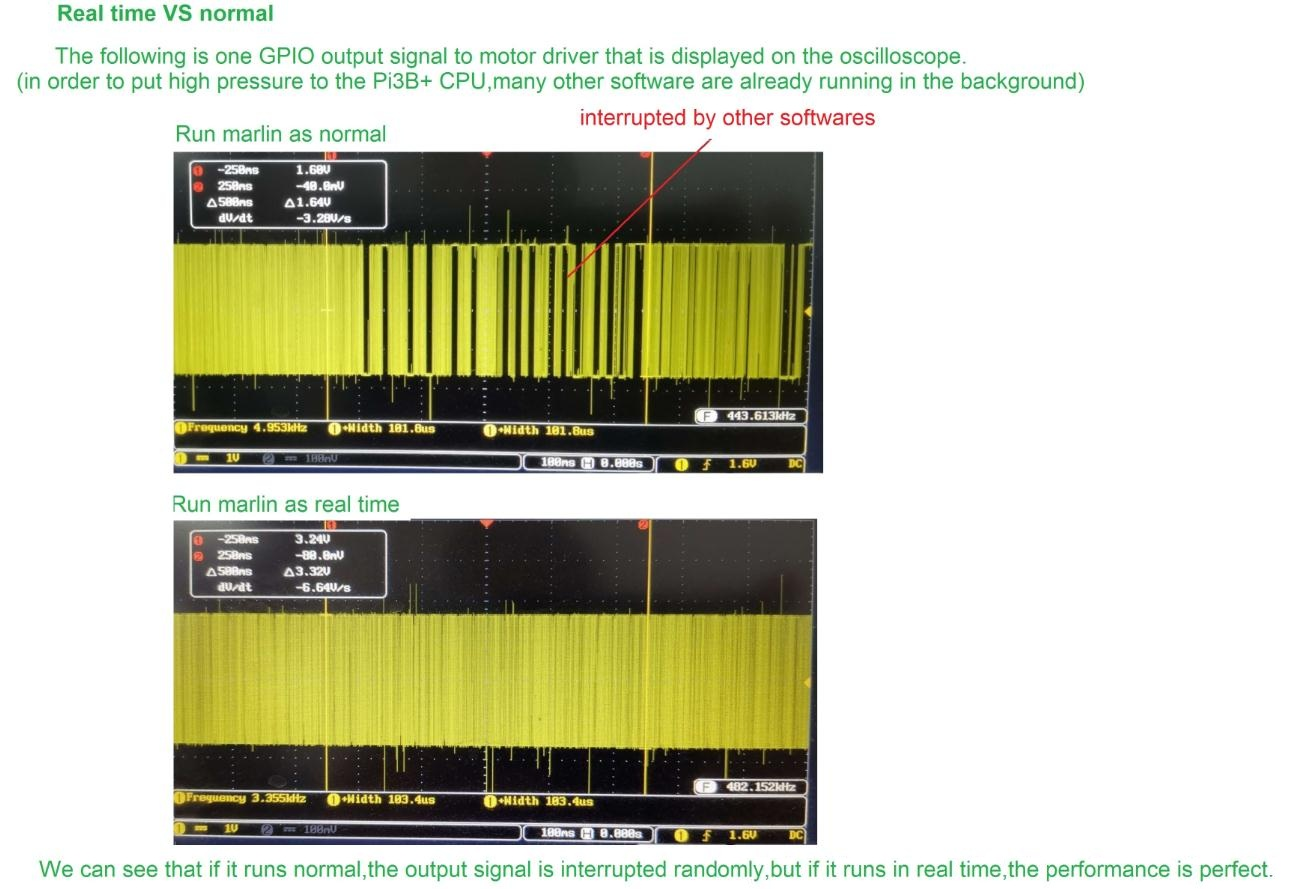
What's more interesting is that there is a firmware (forgot the name) that completely runs on RPI!! they do use real time kernel but they step drivers from GPIO pins on the RPI itself !!! I was very skeptical that can work but I seen the tests and ... I still have hard time believing it
-
@ChrisP, I would disagree on this being a bug. The controllers job is to do what it’s told. If you call for 100x1 it should treat it as 100 moves and include acceleration/deceleration as such. If you want an optimiser that should be a separate processing path. Be it in the slicer or in an operation between the slicer and execution of the print.
Adding the complexity in the controller increases the likely good of defects in the control loop and doesn’t work as expected for a computer processor... to do it’s job as it’s told.
-
@arhi said in Where is the difference - 10 times X1 vs 1 times X10:
What's more interesting is that there is a firmware (forgot the name) that completely runs on RPI!! they do use real time kernel but they step drivers from GPIO pins on the RPI itself !!! I was very skeptical that can work but I seen the tests and ... I still have hard time believing it
If it's using a real-time kernel on the Pi then that seems entirely reasonable to me, if the Pi has enough I/O pins.
Another option would be to use a quad-core Pi with a real-time kernel running on one core and Linux on the other 3.
-
-
Before switching to Duet out of curiosity I ran LinuxCNC on a Pi using a PREEMPT_RT patched kernel with ST L6470 stepper drives connected over SPI. Analog I/O was handled by an STM32F103 'blue pill' board over USB/HID (which provides an upper bound on latency also)
That PREEMPT_RT takes care of the realtime requirements and the system ran flawless. My switch to Duet was more out of curiosity than necessity.Maybe PREEMPT_RT is something to consider for DSF? It will soon be in the mainline kernel, although they keep saying that for 10 years or so.
-
Regards the Raspberry Pi commanding direct to steppers I believe they used one of the memory interfaces.
@dc42 the parsing is not a real-time task. So long as a slice can be prepped at least as quick as the machine process one you don't have an issue.
Running 3 P3Steel with Duet 2. Duet 3 on the shelf looking for a suitable machine. One first generation Duet in a Logo/Turtle style robot!
-
@DocTrucker Running a second, intermediate process to 'clean up the gcode' means, at least some level, altering the gcode. So people have to get comfortable with that, and the hassle of running a second process on their files.
I believe Klipper effectively does all the step generation on the RPi, and uses connected controllers as 'dumb' microcontrollers, feeding them step pulses, though I confess I've barely looked at Klipper. Maybe a way to do this on Duet would be to run the RRF in a virtual machine (so you get to use the printer's config.g), run a simulation of the gcode file (built in to RRF), but record the output to a file, somehow adjust for speed/timing, then have a function in RRF on the board that can 'read' a raw step file. Maybe this could be done through RPi/DSF?
Circling back to the original topic (sort of), what really needs to happen is for Slicers to allow import of CAD files, eg .OBJ, and export G2 and G3 arcs, and G5 cubic bezier curves. Then we get rid of stl approximations, and gcode that has any curves generates a much more compact file, and reduces the problem of buffer or cache underruns. It seems generating steps from G5 (at least, not sure about G2/3 but think they use sin/cos) doesn't come with too much of a computational overhead for the microcontroller (see this from 2016 https://github.com/MarlinFirmware/Marlin/issues/3022 ). So perhaps then it's not necessary to either generate step code on the PC, or have very powerful microcontrollers, once slicers get smarter!
Ian
closed Ability to follow cubic Bézier splines #3022
TronXY X5S with Duet 3 MB6HC and Roto toolboard : Cartesian bed-slinger with Duet 3 Mini 5+ WiFi and 1LC : RRP Fisher Delta v1 with Duet 2 Maestro : Polargraph with Duet 2 WiFi
-
@DocTrucker said in Where is the difference - 10 times X1 vs 1 times X10:
Regards the Raspberry Pi commanding direct to steppers I believe they used one of the memory interfaces.
@dc42 the parsing is not a real-time task. So long as a slice can be prepped at least as quick as the machine process one you don't have an issue.
It certainly is a real-time task when the GCode file has a large number of short segments in a row. Planning is even more so.
There is a big difference between what you can get away with under most conditions, and what you can get away with under difficult conditions.
Duet WiFi hardware designer and firmware engineer
Please do not ask me for Duet support via PM or email, use the forum
http://www.escher3d.com, https://miscsolutions.wordpress.com -
@droftarts I was implying the intermediate software be written in such a way that it runs within DSF or externally on whole files.
So far as people getting nervous about gcode manipulation there are masses of commands that already manipulate the gcode before it is printed. The function being discussed here (clean up consecutive parrallel vectors, remove unorocessable data etc) to resolve the OP problem is little different.
-
I think we are being very weak in terminology here. An extension on the arguments used to call parsing a real time exercise could be used to argue finance software needs to be real time because accounts need to be filed at a specific date.
My understanding of real time is that something needs to be done at a specific time, within a tight tollerance, not early or late. Much like the exact timings of the step pulses to the drivers. If things fall out of sequence there at best things get noisey when worse for example the timing glitches set up resonances that stall the steppers. Parsing is time critical in the build, but it doesn't matter if the parse executes far quicker than realtime (hense it could parse a gcode and output gcode rather than data direct to path planners), so long as there is always enough parsed data to keep the path planner for the steppers full. Much like keeping the buffer full on a cd burn.
What I'm suggesting is a clean up parse of the gcode as a clean up here to sort issues like the consequtive parrallel vectors rather than have the real time processes bogged down by it which is what is happening here.
Create a cube in CAD, mesh it, slice it, and the majority of systems will give you eight vectors per slice rather than four. Add rounds to one edge on the top surface and two of the sides are likely to have a far higher quantity of vectors.
This is trash data that the processor has to work through and limits the effectiveness of look-ahead path planning. Very easy to parse out.
Yeah other data formats have been muted but they tend to require many special cases in the slicing to cope with specific geometric features. The beauty of slicing mesh data is it's far closer to one size fits all. Forcing the printer to follow that path exactly is a failure to grasp that the meah data itself is an approximation too. An ideal would be retention of information used to create the CAD, so path planners know how much they can deviate before they are introduing more error than the mesh generation.
Running 3 P3Steel with Duet 2. Duet 3 on the shelf looking for a suitable machine. One first generation Duet in a Logo/Turtle style robot!
-
-
Somewhere up there, DC42 pointed out it will always be possible to generate GCode that exceeds any given planners ability to read/parse/plan/execute. My example would be: Keep lowering the distance moved per command, and the result is an arbitrary number of lines needed to reach the same endpoint of the move. The 300 X1 in a row is probably an example of this.
-
Therefore this whole discussion is only relevant if it affects actual (useful) gcode as generated by slicers or CAM or similar. (Dave said this as well)
Those two points combined seem to have triggered lots of discussion about optimizing G-code between the slicer and the actual execution in the firmware. Where/when/how much to optimize... lots of good discussion. At the same time, point 2 makes me really wonder if that optimization is needed?
Delta / Kossel printer fanatic
-
-
@DocTrucker said in Where is the difference - 10 times X1 vs 1 times X10:
My understanding of real time is that something needs to be done at a specific time, within a tight tollerance, not early or late.
Well, "real time" usually, in IT industry, means that the time is known. For e.g. MySQL Cluster Carrier Grade Edition (MCCGE) is real-time rdbms. The query will either finish in known time or it will fail (with temporary error and you can decide to retry or move forward depending on what you need at that moment). The major part is that you know/can calculate the time and not have that time be dependent on stuff you cannot control (e.g. mjpegstreamer running in parallel). While most ppl when they talk assume real-time means fast, the time does not need to be short at all, it just need to be known for the system to be real-time.
With regards to klipper it works more less like LinuxCNC, so like LinuxCNC uses HAL to send stepping info to the drivers connected on some bus (pci, usb, ethernet), klipper sends similar info to it's drivers connected on usb. Does the klipper itself require RT or not I could not say but I tend to trust that @dc42 knows what's he's talking about as duet3 and CAN drivers are IMHO same thing. He sends the stepping instructions to CAN drivers just like klipper send it trough usb or linuxCNC via HAL trough any of the supported busses.
-
@Danal said in Where is the difference - 10 times X1 vs 1 times X10:
At the same time, point 2 makes me really wonder if that optimization is needed?
As I mentioned, I did the test, because of a lot of disturbance with octoprint+marlin and curves where running gcode through octoprint will create blobs and other artifacts on the print while running from sdcard would print ok. The major problem was found to be the small serial port buffer on the marlin so it's unable to receive enough statements to run uninterrupted. While increasing the buffer solves 90% of the issues, 10% still exist and those were more/less tracked to both SBC and marlin CPU not being able to calculate CRC fast enough to have enough G-Code pass trough and finally if the movements are even shorther the issue with parser & planner on the 8bit mcu unable to execute code. All this with real world sames, STL generated by fusion or solidworks on "high" settings, sliced with "printer profile" in cura or prusa or s3d..
I never had any of those problems with smoothieware so when I got my hands on the duet2ethernet it was the first thing I tested and it passed with flying colors, the stuff marlin could not print from SD card duet printed through USB.
So I'd say - real world problems don't exist with RRF.
BUT!
The work I read on that I mentioned few times, that's ATTM just a plugin for octoprint but that actually recodes the G-Code optimizing it by matching curves on top of the existing code reducing both code size and code complexity is IMHO "next step" in home printers evolution. It can be run as stand alone optimize if=lalala.gcode of=lalala-optimized.gcode for non octoprint users (I prefer it that way even for octoprint so it don't do stuff on the fly) and "tomorrow" it can be a plugin for cura/ps/ideamaker/s3d...
Now, I heard KISS beta version have this already in the slicer, dunno free or commercial version I never used that slicer so can't say, but if anyone is, check beta version, advanced options, curve matching or something like that ... there are branches of slic3r with curve matching too .. so probably in the near future
.. maybe even f360 ..But it's def. not something firmware needs to do. Nice thing to have externally but firmware just need to support and properly handle G2 and G3
-
Klipper's central tasks do not require any RTOS.
Klipper makes sure the Pi based portions of the system "stay ahead" of the "stepper driver boards". I don't know by how much it attempts to stay ahead. This was specifically designed so that the stepper boards are 'real time' pulse generators and the 'central' (e.g. Pi) is absolutely NOT 'real time', so that the central parts are able to tolerate the variances in execution that come from being a task under Linux.
I seem to remember Dave saying that Duet 3 (with or without Pi) sends commands on CAN about 1/2 second before they are needed by the expansion or tool board. Similar idea. It is true that the 6HC is running an RTOS, but the central-to-can pieces are 'in advance' so that the actual pulses can happen 'real time', later, as synchronized by tick count.
Conceptually similar; different in detail.
-
@Danal said in Where is the difference - 10 times X1 vs 1 times X10:
Klipper's central tasks do not require any RTOS.
Every task that has a to meet a deadline to maintain the expected results/performance is a real time task. Step pulse generation is hard real-time, so hard that it is normally done by an ISR, not an RTOS task. Planning is a softer real-time task, because occasional underruns in the movement queue can be tolerated. Reading and parsing GCode commands from file is softer still.
From an engineering POV, Klipper should be using a RTOS for the planner. It gets away without using one because there is usually enough CPU power to keep up, especially when using a multicore Pi and the Pi is not being used for anything else (e.g. slicing).
BTW on Duet 3 we pre-parse the GCode file on the Pi, so the GCodes fed to the Duet are already partly processed.
It will be interesting to see how Klipper and Duet 3 compare when printing "difficult" GCode files and running other tasks such as slicing, USB webcam etc. on the Pi at the same time.
Duet WiFi hardware designer and firmware engineer
Please do not ask me for Duet support via PM or email, use the forum
http://www.escher3d.com, https://miscsolutions.wordpress.com -
@dc42 said in Where is the difference - 10 times X1 vs 1 times X10:
It will be interesting to see how Klipper and Duet 3 compare when printing "difficult" GCode files and running other tasks such as slicing, USB webcam etc. on the Pi at the same time.
klipper users normally run octoprint with ton of plugins (some quite heavy on the cpu) in parallel, most run mpegstreamer there with usb or rpi camera but I know more tha one running 3-4 usb cameras there with as many streamers in parallel .. noone reported a problem. Have not tried myself but follow klipper groups closely as I was planing to. Also I use octoprint on my non-duet printers so have some experience on the load plugins can put on the sbc. No clue how they do it but they do. I guess they just have a large queue, you can delay step starting 10 seconds easy and have 10 seconds buffer for "glitches" and "problems" with cpu alotment
-
@dc42 Can't speak for a Pi specifically, but my Jetson Nano runs a web cam, @Danal 's DuetLapse, ustreamer, and DueUI in a Chrome browser that actually shows the web cam stream. With all that running it keeps the 4 core Nano at about 40% CPU. With that going on, I can print Covid-19 masks (which are all curves) at 100mm/s without any issue at all.
-
@dc42 said in Where is the difference - 10 times X1 vs 1 times X10:
Every task that has a to meet a deadline to maintain the expected results/performance is a real time task. Step pulse generation is hard real-time, so hard that it is normally done by an ISR, not an RTOS task. Planning is a softer real-time task, because occasional underruns in the movement queue can be tolerated. Reading and parsing GCode commands from file is softer still.
From an engineering POV, Klipper should be using a RTOS for the planner. It gets away without using one because there is usually enough CPU power to keep up, especially when using a multicore Pi and the Pi is not being used for anything else (e.g. slicing).
Good clarity. Missing a deadline, even at the medium soft levels, ruins a print. Running "far enough in advance to usually get away with it" is not the same.